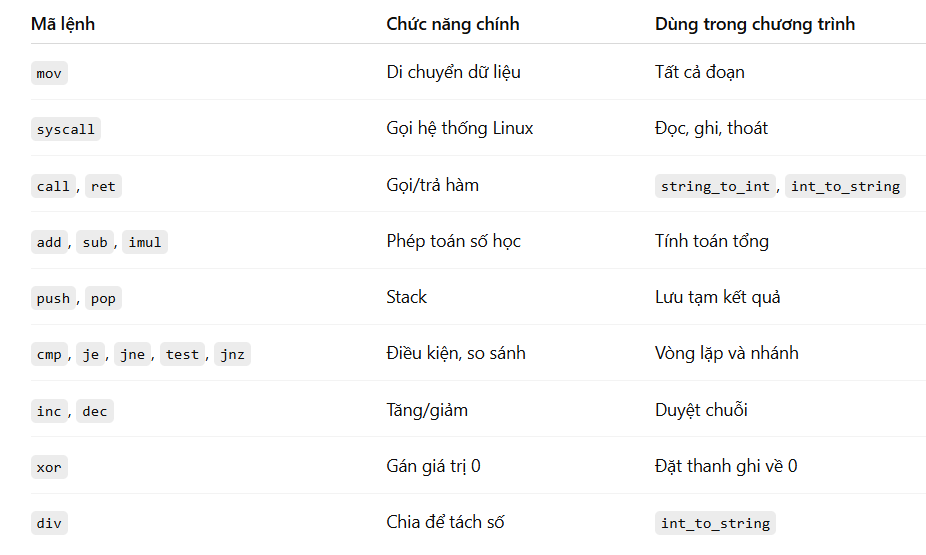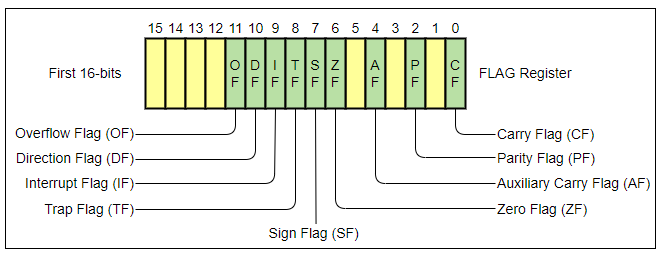
Thanh ghi cờ là một thanh ghi đặc biệt trong bộ xử lý, nó chứa nhiều bit phản ánh kết quả của các phép tính, cũng như trạng thái của bộ xử lý. Trong đó có 5 cờ liên quan đến các phép toán số học, chúng sẽ được bật hoặc tắt dựa trên kết quả của lệnh tính toán trước đó. Các cờ đó là:
- Carry flag (CF): bằng 1 nếu phép tính có mượn. Hay nói cách khác, CF bằng 1 nếu (A + B) có kết quả lớn hơn số bit có thể chứa, hoặc nếu A < B nếu là phép trừ.
- Parity flag (PF): bằng 1 nếu tổng số bit 1 trong byte thấp nhất của kết quả là chẵn. Ví dụ kết quả là 0b_00001111 thì PF = 1 (số bit 1 là 4).
- Auxiliary Carry flag (AF): Bằng 1 nếu có xảy ra “nhớ” với 4 bit thấp nhất (Tương tự CF nhưng chỉ áp dụng cho 4 bit thấp nhất).
- Zero flag (ZF): Bằng 1 nếu kết quả bằng 0.
- Sign flag (SF): bằng 1 khi bit dấu (bit lớn nhất) của kết quả là 1, biểu thị đây là một kết quả âm.
Các cờ được sử dụng trong các phép nhảy có điều kiện, các lệnh kiểu như JZ (Jump if Zero), JNZ (Jump if Not Zero), JC (Jump if Carry), JG (Jump if Greater), JE (Jump if Equal)… đều dựa trên các cờ tương ứng để quyết định.
Note: mỗi nhóm 4 bit (biểu thị bằng một số hệ 16) còn được gọi là 1 nibble (Mỗi byte có 2 nibble).